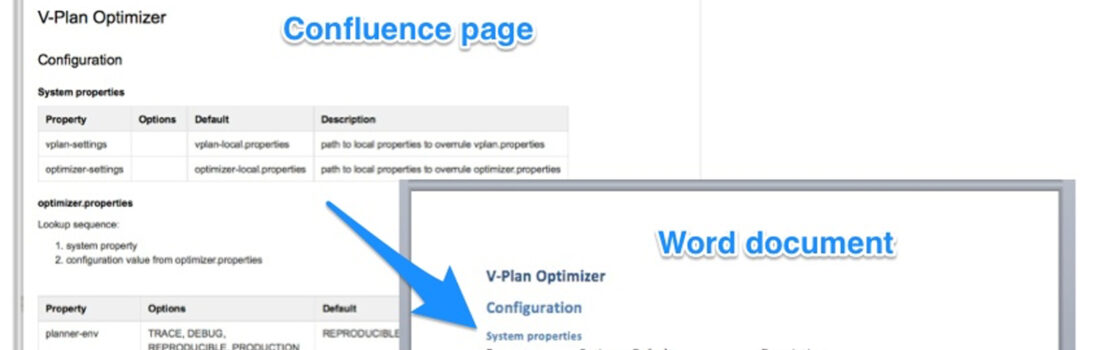
Problem:
Your company is using Confluence and this is the place, where the employees write their documents, maintain the links between the pages etc.
You have to deliver high-quality documents (documentation, manuals etc.) to your customer, so you have to produce PDF or Word-files. The customer wants you to use specific templates with header-page, logo, table of contents.
How can you bring the content of the Confluence pages into the documents for shipping?
You could write the documentation with word, you can copy-paste the confluence pages into word files, you can use the export functions of confluence to export pages as PDF or Word files, but: all those options are either manual effort, hard to maintain or do not produce documents in the format that you can control.
What you want is a customizable solution, that even can be 100% automated to have docments with up-to-date content ready to deliver at any time.
Idea:
So the idea is to use the Confluence2MD tool to retrieve the pages out of confluence and convert them into a Markdown file. A markdown file is a text file and the PanDoc tool, can convert such files into various formats, e.g. Word or PDF.
You can use master-/child documents to bring the generated documents into a document that contains a table-of-content etc.
Use Confluence2MD from maven-central
Confluence2MD is a tool written by Viaboxx, published as open source (Apache 2.0 license). The artifacts can be retrieved from maven-central:
[codesyntax lang="xml" lines="no"] <pre><dependency> <groupId>de.viaboxx.markdown</groupId> <artifactId>confluence2md</artifactId> <version>1.5.2</version> <classifier>fat</classifier> </dependency></pre> [/codesyntax]
confluence2md supports to retrieve your confluence pages with the REST/HTTP API and converts a document hierarchy into a markdown file. It supports links to other chapters or external URLs, tables, lists, codeblocks and images. It even renders diagrams described with the PlantUML syntax as images.
To run the tool, you need a JRE (java version 7 or newer).
Install Pandoc
To convert the Markdown file to any document format, you need to install Pandoc.
see http://johnmacfarlane.net/pandoc/
Usage
See the usage of confluence2md about the possible options:
- -m wiki|file|url
specify input format/processing mode (default: wiki) - -o file
specify output format, charset=UTF-8 (default: stdout, charset=file.encoding of plaform) - -oa file
specify output format, charset=UTF-8 – open for append! - -v true
for verbose output (default: false) - -u user:password
to use HTTP-Basic-Auth to request the URL (default: no auth) - -depth -1..n
the depth to follow down the child-pages hierarchy. -1=infinte, 0=no children (default: -1) - -server URL
URL of confluence server. used in wiki-mode (default: https://viaboxx.atlassian.net/wiki) - -plantuml
turn off integrated run of PlantUML to render diagrams (default is to call PlantUML automatically) - -a folder
download folder for attachments (default: attachments) - +H true/false true: document hierarchy used to generate page header format type (child document => h2 etc) (default: true)
- +T true/false
true: title transformation ON (cut everything before first -) (default: true) - +RootPageTitle true/false
true: generate header for root page, false: omit header of root page (default: true) - +FootNotes true/false true:generate foot notes, false: no foot notes (default: true)
- -maxHeaderDepth 1..n the maximum header depth that will be rendered as a header, deeper will only rendered as bold title (default: 5)
- last parameter:
the file to read (-m file) or the URL to get (-m url) or the pageId to start with (-m wiki)
Call the pandoc tool to convert the markdown file (.md) to the document format of your choice.
Example
[codesyntax lang="bash" lines="no"] <pre>java -jar confluence2md-fat.jar +T true +H true +RootPageTitle true -v -o docFromWiki.md -u myUser:myPassword -server https://viaboxx.atlassian.net/wiki 3408268 pandoc -f markdown+hard_line_breaks -N --template default.tex -o docFromWiki.docx docFromWiki.md</pre> [/codesyntax]
- “3408268” is a pageId in the wiki at “https://viaboxx.atlassian.net/wiki”
- the wiki requires basic authentication as user=myUser with password=myPassword
- “+T true” enables title-transformation.
e.g. when a Confluence-page is named “Technical manual – Introduction” the chapter in the result document would be transformed to “Introduction”.
The text after the first “-” will be used as chapter title.
This helps to get a determined sequence of sub-chapters: You can name the child pages as “1 – Install”, “2 – Getting Started”, etc. because Confluence returns them ordered by page title alphabetically. - The result from running confluence2md is a markdown file named “docFromWiki.md”
- The result from running pandoc is a word docx file named “docFromWiki.docx”
You can now find the sources in github: https://github.com/viaboxxsystems/confluence2md
Released artifacts can be found in maven-central.
de.viaboxx.markdown
confluence2md
1.5.2
or
de.viaboxx.markdown
confluence2md
2.0